Music
April 30, 2015
last chance for the apes
April 30, 2015
| << | >> | open webamp |

(retroactively posted Nov 2015)
Recordings:
no fools flat
Comment...
commit f94d5a07541a672b4446248409568c20bca9487d
Author: Justin <justin@localhost>
Date: Sun Sep 11 21:52:27 2005 +0000
Vss2Git
diff --git a/jmde/mediaitem.h b/jmde/mediaitem.h*
new file mode 100644
index 0000000..52b8a8f
--- /dev/null
++ b/jmde/mediaitem.h
@@ -0,0 +1,37 @@
#ifndef _MEDIAITEM_H_
#define _MEDIAITEM_H_
#include "pcmsrc.h"
#include "../WDL/string.h"
class MediaItem
{
public:
double m_position;
double m_length;
double m_startoffs;
double m_fade_in_len, m_fade_out_len;
int m_fade_in_shape, m_fade_out_shape;
double m_volume, m_pan;
WDL_String m_name;
PCM_source *m_src;
};
class AudioChannel
{
WDL_PtrList<MediaItem> m_items;
double m_volume, m_pan;
bool m_mute, m_solo;
WDL_String m_name;
// recording source stuff, too
// effect processor list
// getsamples type interface
};
#endif
* Trivia: guess what jmde (JMDE) stands for?
..and to think, back when we used VSS we didn't even have commit messages! Soon after, "AudioChannel" became instantiable and went on to be known as "MediaTrack", and as one would hope many other things ended up changing.
Wow, 9 years have gone by.
I've been having a blast this week working on something that let me make this:
The interesting bit of this is not the contents of the video itself -- 3 hasty first-takes with drums, bass, and guitar, each with 2 cameras (a Canon 6D and a Contour Roam 2) -- but how it was put together.
I've spent much of the last week experimenting with improving the video features of REAPER, specifically adding support for fades and video processing. This is a ridiculously large can of worms to open, so I'm keeping it mostly contained in my office and studio.
Working on video features is reminding me of when I was first starting work on what would become REAPER: I was focused on doing things that I could use then and there for things I wanted to make. It is incredibly satisfying to work this way. So now, I'm doing it in a branch (thank you git), as it is useful for me, but so incredibly far from the usability standard that REAPER represents now (even if you argue that REAPER is poorly designed, it's still 100x better than what I've done this week). You can't go put half-baked, poor performing, completely-programmer-oriented video features into a 9 year old program.
The syntax has since been simplified a bit, but basically you have meta-video items which can combine other video items on the fly. So you can write new transitions or customize existing transitions while you work (which is something I love about JSFX).
I'm going to keep working on this, it might get there someday. Former Vegas fans, fear not, REAPER isn't going to become a video editor. I'm just going for a taste...
6 Comments
If x is signed and is negative, division rounds towards 0, whereas the shift rounds towards negative infinity, but in situations where rounding of negative values is not important, I had generally assumed that modern compilers would generate similarly efficient code (reducing x/256 into a single x86 sar instruction).
It turns out, testing with a two modern compilers (and one slightly out of date compiler), this is not the case.
Here is the C code:
void b(int r);
void f(int v)
{
int i;
for (i=0;i<v/256;i++) b(v > 0 ? v/65536 : 0);
}
void f2(int v)
{
int i;
for (i=0;i<(v>>8);i++) b(v > 0 ? v >> 16 : 0);
}
Ideally, a compiler should generate identical code for each of these functions. In the case of the loop counter, if v is less than 0, how it is rounded makes no difference. In the case of the parameter to b(), the code v >> 16 is only evaluated if v is known to be above 0.
Let's look at the output of some compilers (removing decoration and unrelated code). I've marked some code as bold to signify instructions that could be eliminated (with slight changes to the surrounding instructions):
f(): # using divides
cmpl $256, %edi
jl LBB0_3 # if v is less than 256, skip loop
# v is known to be 256 or greater.
movl %edi, %ebx
sarl $31, %ebx # ebx=0xffffffff if negative, 0 if non-negative
movl %ebx, %r14d
shrl $24, %r14d # r14d=0xff if negative, 0 if non-negative
addl %edi, %r14d # r14d = (v+255) if v negative, v if v non-negative
sarl $8, %r14d # r14d = v/256
shrl $16, %ebx # this will make ebx 65535 if v negative, 0 if v non-negative
addl %edi, %ebx # ebx = (v+65535) if v negative, v if v non-negative
sarl $16, %ebx # ebx = v/65536
# interestingly, the optimizer used its knowledge of v being greater than 0 to remove the ternary conditional expression completely.
xorl %ebp, %ebp
LBB0_2:
movl %ebx, %edi
callq _b
incl %ebp
cmpl %r14d, %ebp
jl LBB0_2
LBB0_3:
f2(): # using shifts
movl %edi, %ebp
sarl $8, %ebp # ebp = v>>8
testl %ebp, %ebp
jle LBB1_3 # if less than or equal to 0, skip
movl %edi, %eax
sarl $16, %eax # eax = v>>16
xorl %ebx, %ebx
testl %edi, %edi
cmovgl %eax, %ebx # if v is greater than 0, set ebx to eax
# the optimizer could also have removed the xorl/testl/cmovgl sequence as well
LBB1_2:
movl %ebx, %edi
callq _b
decl %ebp
jne LBB1_2
LBB1_3:
In the first function (division), the LLVM optimizer appears to have removed the ternary expression (checking to see if v was greater than 0), likely because it knew that if the loop was running, v was greater than 0. Unfortunately, it didn't apply this knowledge to the integer divisions of v, which would have allowed it to not generate (substantial) rounding code.
f(): # using divides
mov eax, ecx
mov ebx, ecx
cdq # set edx to 0xffffffff if v negative, 0 otherwise
movzx edx, dl # set edx to 0xff if v negative, 0 otherwise
add eax, edx # eax = v+255 if v negative, v otherwise
sar eax, 8 # eax = v/256
test eax, eax
jle SHORT $LN1@f # skip loop if v/256 is less than or equal to 0
mov QWORD PTR [rsp+48], rdi
mov edi, eax # edi is loop counter
$LL3@f:
test ebx, ebx
jle SHORT $LN6@f # if v is less than or equal to 0, jump to set eax to 0
mov eax, ebx
cdq # set edx to 0xffffffff if v negative, 0 otherwise
movzx edx, dx # set edx to 0xffff if v negative, 0 otherwise
add eax, edx # eax = v+65535 if v negative, v otherwise
sar eax, 16 # eax = v/65536
jmp SHORT $LN7@f
$LN6@f:
xor eax, eax
$LN7@f:
mov ecx, eax
call b
dec rdi
jne SHORT $LL3@f
mov rdi, QWORD PTR [rsp+48]
$LN1@f:
f2(): # using shifts
mov eax, ecx
mov ebx, ecx
sar eax, 8 # eax = v>>8
test eax, eax
jle SHORT $LN1@f2 # skip loop if v>>8 is less than or equal to 0
mov QWORD PTR [rsp+48], rdi
mov edi, eax
$LL3@f2:
test ebx, ebx
jle SHORT $LN6@f2 # if v is less than or equal to 0, jump to set ecx to 0
mov ecx, ebx
sar ecx, 16 # ecx = v>>16
jmp SHORT $LN7@f2
$LN6@f2:
xor ecx, ecx
$LN7@f2:
call b
dec rdi
jne SHORT $LL3@f2
mov rdi, QWORD PTR [rsp+48]
$LN1@f2:
VS 2013 generates different rounding code for the division, using cdq/movzx (or cdq/and if shifting by something other than 8 or 16 bits).
f(): # using divides
testl %edi, %edi
movl %edi, %ebp # ebp = edi = v
leal 255(%rbp), %r12d # r12d = v+255
cmovns %edi, %r12d # set r12d to v, if v is non-negative (otherwise r12d was v+255)
sarl $8, %r12d # r12d = v/256
testl %r12d, %r12d
jle .L14 # if r12d is less than or equal to 0, skip
movl %edi, %r14d
xorl %ebx, %ebx # ebx is loop counter
xorl %r13d, %r13d
sarl $16, %r14d # r14d = v>>16
.L13:
testl %ebp, %ebp
movl %r13d, %edi
cmovg %r14d, %edi # if v is greater than 0, use v>>16 instead of 0
addl $1, %ebx
call b
cmpl %r12d, %ebx
jl .L13
.L14:
f2(): # using shifts
movl %edi, %r12d
sarl $8, %r12d
testl %r12d, %r12d
movl %edi, %ebp
jle .L6 # skip loop if (v>>8) is less than or equal to 0
movl %edi, %r14d
xorl %ebx, %ebx # ebx is loop counter
xorl %r13d, %r13d
sarl $16, %r14d # r14d = (v>>16)
.L5:
testl %ebp, %ebp
movl %r13d, %edi
cmovg %r14d, %edi # if v is greater than 0, use v>>16 instead of 0
addl $1, %ebx
call b
cmpl %r12d, %ebx
jl .L5
.L6:
gcc 4.4 does an interesting job, using lea to generate v+255, and then cmovns to replace it with v if v is non-negative. It doesn't bother generating rounding code for v/65536, but it does still generate rounding code for v/256, even though any non-positive result for v/256 is treated the same way throughout. Also, gcc doesn't eliminate the non-varying ternary expression, nor put the constant v/65536 or v>>16 outside of the loop.
I'm not sure what to say here -- modern compilers can generate a lot of really good code, especially looking at floating point and SSE, but this makes me feel as though some of the basics have been neglected. If I were a better programmer I'd go dig into LLVM and GCC and submit patches.
I should have also tested ICC, but I've spent enough time on this, and the only ICC version we use is old enough that I would just regret not using the latest.
For comparison, here is what I would like to see LLVM generate for f():
f(): # using divides cmpl $256, %edi jl LBB0_3 # if v is less than 256, skip loop movl %edi, %ebx movl %edi, %ebp shrl $8, %ebx # ebx = v/256, since v is non-negative shrl $16, %ebp # ebp = v/65536, since v is non-negative LBB0_2: movl %ebp, %edi callq _b decl %ebx jnz LBB0_2 LBB0_3:Performance-wise, I'm sure they wouldn't differ in any meaningful way, but the decrease in size would be nice.
The above performance gain aside, I am still not satisfied with the bitmap drawing performance on recent OSX versions, which has led me to benchmark SWELL's blitting code. My test uses the LICE test application, with a screen full of lines, an opaque NSView, and 720x500 resolution.
OSX 10.6 vs 10.8 on a C2D iMac
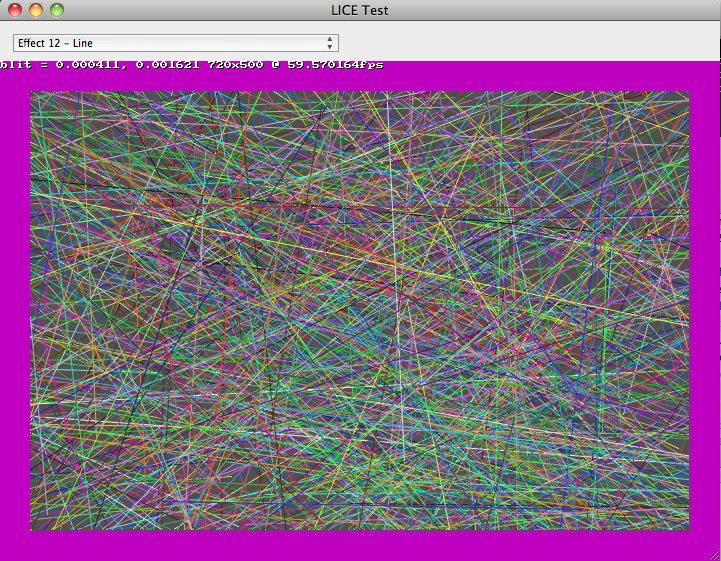
My (C2D 2.93GHz) iMac running 10.6 easily runs the benchmark at close to 60 FPS, using about 45% of one core, with the BitBlt() call typically taking 1ms for each frame.
Here is a profile -- note that CGContextDrawImage() accounts for a modest 3.9% of the total CPU use:
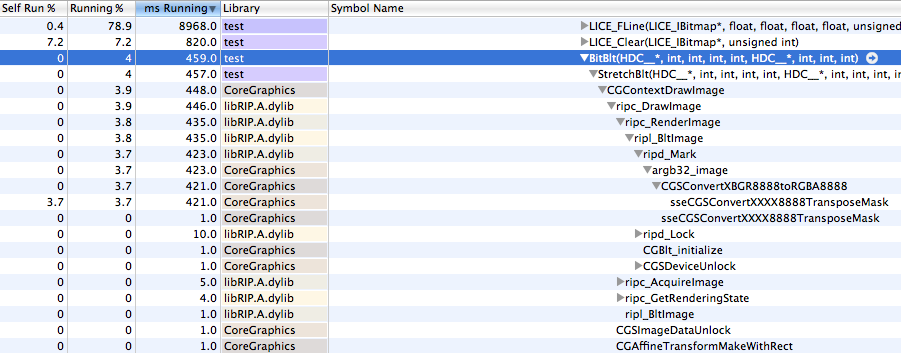
It might be possible to reduce the work required by changing our bitmap representation from ABGR to RGBA (avoiding sseCGSConvertXXXX8888TransposeMask and performing a memcpy() instead), but in my opinion 1ms for a good sized blit (and less than 4% of total CPU time for this demo) is totally acceptable.
I then rebooted the C2D iMac into OSX 10.8 (Mountain Lion) for a similar test.
Running the same benchmark on the same hardware in Mountain Lion, we see that each call to BitBlt() takes over 6ms, the application struggles to exceed 57 FPS, and the CPU usage is much higher, at about 73% of a core.
Here is the time sampling of the CGContextDrawImage() -- in this case it accounts for 36% of the total CPU use!
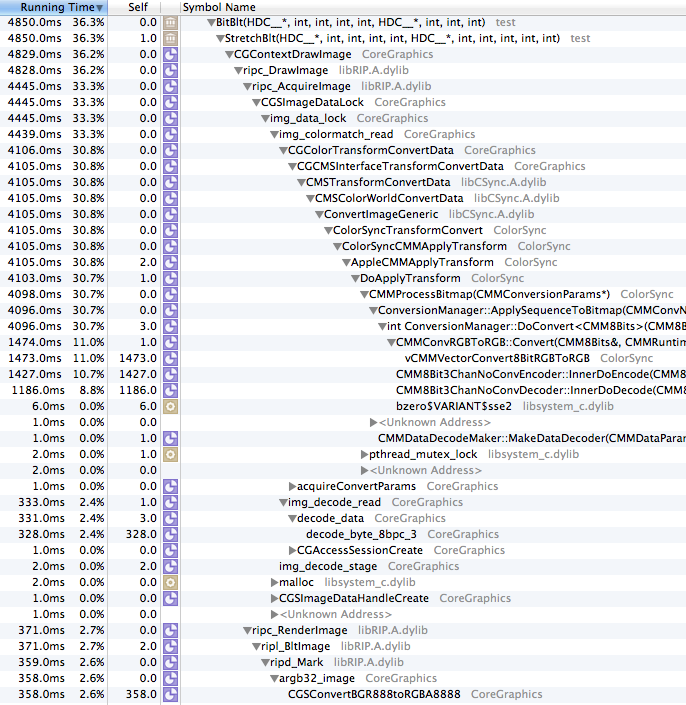
Looking at the difference between these functions, it is obvious where most of the additional processing takes place -- within img_colormatch_read and CGColorTransformConvertData, where it apparently applies color matching transformations.
I'm happy that Apple cares about color matching, but to force it on (without allowing developers control over it) is wasteful. I'd much rather have the ability transform the colors before rendering, and be able to quickly blit to screen, than to have to have every single pixel pushed to the screen color transformed. There may be some magical way to pass the right colorspace value to CGCreateImage() to bypass this, but I have not found it yet (and I have spent a great deal of time looking, and trying things like querying the monitor's colorspace).
That's what OpenGL is for!
But wait, you say -- the preferred way to quickly draw to screen is OpenGL.
Updating a complex project to use OpenGL would be a lot of work, but for this test project I did implement a very naive OpenGL blit, which enabled an OpenGL context for the view and created a texture for drawing each frame, more or less like:
glDisable(GL_TEXTURE_2D);
glEnable(GL_TEXTURE_RECTANGLE_EXT);
GLuint texid=0;
glGenTextures(1, &texid);
glBindTexture(GL_TEXTURE_RECTANGLE_EXT, texid);
glPixelStorei(GL_UNPACK_ROW_LENGTH, sw);
glTexParameteri(GL_TEXTURE_RECTANGLE_EXT, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexImage2D(GL_TEXTURE_RECTANGLE_EXT,0,GL_RGBA8,w,h,0,GL_BGRA,GL_UNSIGNED_INT_8_8_8_8, p);
glBegin(GL_QUADS);
glTexCoord2f(0.0f, 0.0f);
glVertex2f(-1,1);
glTexCoord2f(0.0f, h);
glVertex2f(-1,-1);
glTexCoord2f(w,h);
glVertex2f(1,-1);
glTexCoord2f(w, 0.0f);
glVertex2f(1,1);
glEnd();
glDeleteTextures(1,&texid);
glFlush();
This resulted in better performance on OSX 10.8, each BitBlt() taking about 3ms, framerate increasing to 58, and the CPU use going down to about 50% of a core. It's an improvement over CoreGraphics, but still not as fast as CoreGraphics on 10.6.
The memory use when using OpenGL blitting increased by about 10MB, which may not sound like much, but if you are drawing to many views, the RAM use would potentially increase with each view.
I also tested the OpenGL implementation on 10.6, but it was significantly slower than CoreGraphics: 3ms per frame, nearly 60 FPS but CPU use was 60% of a core, so if you do ever implement OpenGL blitting, you will probably want to disable it for 10.6 and earlier.
Core 2 Duo?! That's ancient, get a new computer!
After testing on the C2D, I moved back to my modern quad-core i7 Retina Macbook Pro running 10.9 (Mavericks) and did some similar tests.
Let's see where the time is spent in the "Normal, Low Resolution" mode:
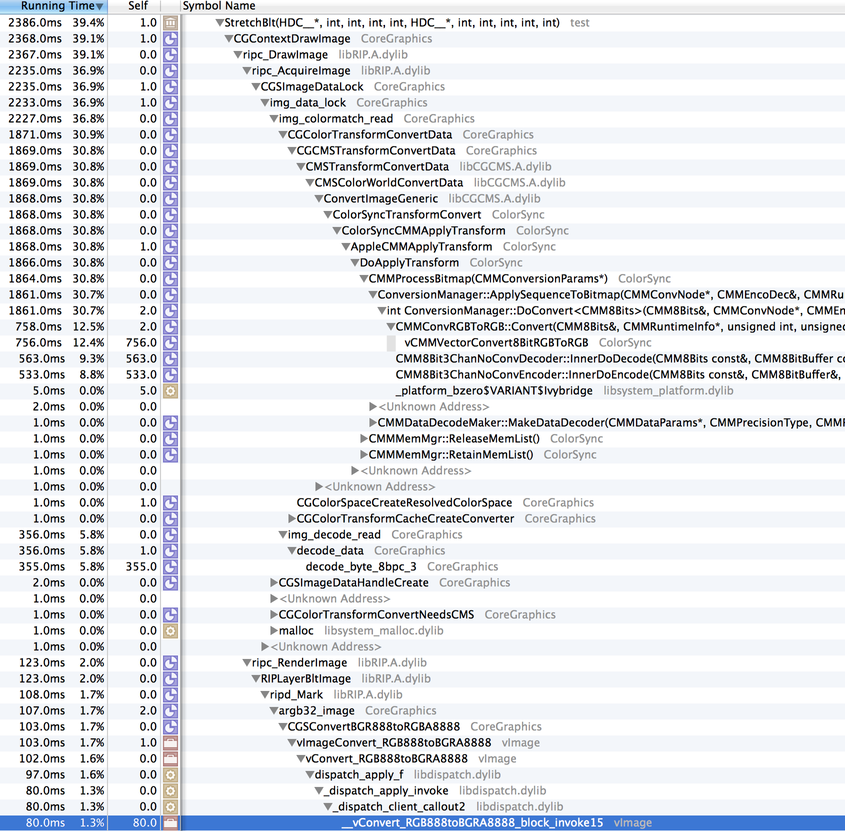
This looks very similar to the 10.8, non-retina rendering, though some function names have changed. There is the familiar img_colormatch_read/CGColorTransformConvertData call which is eating a good chunk of CPU. The ripc_RenderImage/ripd_Mark/argb32_image stack is similar to 10.8, and reasonable in CPU cycles consumed.
Looking at the Low Resolution mode, it really does behave similar to that of 10.8 (though it's depressing to see that it still takes as long to run on an i7 as 10.8 did on a C2D, hmm). Let's look at the full-resolution Retina mode:
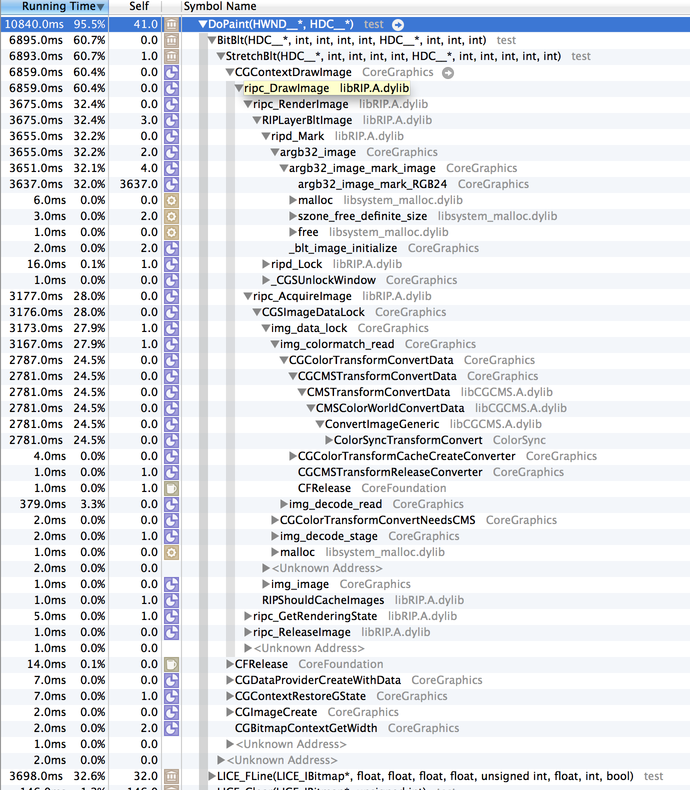
img_colormatch_read is present once again, but what's new is that ripc_RenderImage/ripd_Mark/argb32_image have a new implementation, calling argb32_image_mark_RGB24 -- and argb32_image_mark_RGB24 is a beast! It uses more CPU than just about anything else. What is going on there?
Conclusions
If you ever feel as if modern OSX versions have gotten slower when it comes to updating the screen, you would be right. The basic method of drawing ixels rendered in a platform-independent fashion to screen has gotten significantly slower since Snow Leopard, most likely in the name of color-accuracy. In my opinion this is an oversight on Apple's part, and they should extend the CoreGraphics APIs to allow manual application of color correction.
Additionally, I'm suspicious that something odd is going on within the function argb32_image_mark_RGB24, which appears to only be used on Retina displays, and that the performance of that function should be evaluated. Improving the efficiency of that function would have a positive impact on the performance of many third party applications (including REAPER).
If anybody has an interest in duplicating these results or doing further testing, I have pushed the updates to the LICE test application to our WDL git repository (see WDL/lice/test/).
Update: July 3, 2014
After some more work, I've managed to get the CPU use down to a respectable level in non-Retina mode (10.8 on the iMac, 10.9/Low Resolution on the Retina MBP), by using the system monitor's colorspace:
CMProfileRef systemMonitorProfile = NULL;
CMError getProfileErr = CMGetSystemProfile(&systemMonitorProfile);
if(noErr == getProfileErr)
{
cs = CGColorSpaceCreateWithPlatformColorSpace(systemMonitorProfile);
CMCloseProfile(systemMonitorProfile);
}
Using this colorspace with CGContextCreateImage prevents CGContextDrawImage from calling img_colormatch_read/CGColorTransformConvertData/etc. On the C2D 10.8, it gets it down to 1-2ms per frame, which is reasonable.However, this mode is appears to be slower on the Retina MBP in high resolution mode, as it calls argb32_image_mark_RGB32 instead of argb32_image_mark_RGB24 (presumably operating on my buffer directly rather than the intermediate colorspace-converted buffer), which is even slower.
Update: July 3, 2014, later
OK, if you provide a bitmap that is twice the size of the drawing rect, you can avoid argb32_image_mark_RGBXX, and get the Retina display to update in about 5-7ms, which is a good improvement (but by no means impressive, given how powerful this machine is). I made a very simple software scaler (that turns each pixel into 4), and it uses very little CPU. So this is acceptable as a workaround (though Apple should really optimize their implementation). We're at least around 6ms, which is way better than 12-14ms (or 29ms which is where we were last week!), but there's no reason this can't be faster. Update (2017): the mentioned method was only "faster" because it triggered multiprocessing, see this new post for more information.
As a nice side effect, I'm adding SWELL_IsRetinaDC(), so we can start making some things Retina aware -- JSFX GUIs would be a good place to start...
5 Comments
oscfmt0 = trackindex;
oscsend(destination, { "/track/%.0f/volume" }, 0.5);
Internally, { xyz } is stored to a string table and inserted as a magic number which refers to that string table entry. It is cheap, but it works.
// @input lines:
// usage: @input devicenameforcode "substring match" [skip]
// can use any number of inputs. devicenameforcode must be unique, if you specify multiple @input lines
// with common devicenameforcode, it will use the first successful line and ignore subsequent lines with that name
// you can use any number of devices, too
@input r24 "ZOOM R"
// @output lines
// usage: @output devicenameforcode "127.0.0.1:8000" [maxpacketsize] [sleepamt]
// maxpacketsize is 1024 by default, can lower or raise depending on network considerations
// sleepamt is 10 by default, sleeps for this many milliseconds after each packet. can be 0 for no sleep.
@output localhost "127.0.0.1:8000"
@init
// called at init-time
destdevice = localhost; // can also be -1 for broadcast
// 0= simplistic /track/x/volume, /master/volume
// 1= /r24/rawfaderXX (00-09)
// 2= /action/XY/cc/soft (tracks 1-8), master goes to /r24/rawfader09
fader_mode=2;
@timer
// called around 100Hz, after each block of @msg
@msg
// special variables:
// time (seconds)
// msg1, msg2, msg3 (midi message bytes)
// msgdev == r24 // can check which device, if we care
(msg1&0xf0) == 0xe0 ? (
// using this to learn for monitoring fx, rather than master track
fader_mode > 0 ? (
fmtstr = { f/r24/rawfader%02.0f }; // raw fader
oscfmt0 = (msg1&0xf)+1;
fader_mode > 1 && oscfmt0 != 9 ? (
fmtstr = { f/action/%.0f/cc/soft }; // this is soft-takeover, track 01-08 volume
oscfmt0 = ((oscfmt0-1) * 8) + 20;
);
val=(msg2 + (msg3*128))/16383;
val=val^0.75;
oscsend(destdevice,fmtstr,val);
) : (
fmtstr = (msg1&0xf) == 8 ? { f/master/volume } : { "f/track/%.0f/volume"};
oscfmt0 = (msg1&0xf)+1;
oscsend(destdevice,fmtstr,(msg2 + (msg3*128))/16383);
);
);
msg1 == 0x90 ? (
msg2 == 0x5b ? oscsend(destdevice, { b/rewind }, msg3>64);
msg2 == 0x5c ? oscsend(destdevice, { b/forward }, msg3>64);
msg3>64 ? (
oscfmt0 = (msg2&7) + 1;
msg2 < 8 ? oscsend(destdevice, { t/track/%.0f/recarm/toggle }, 0) :
msg2 < 16 ? oscsend(destdevice, { t/track/%.0f/solo/toggle }, 0) :
msg2 < 24 ? oscsend(destdevice, { t/track/%.0f/mute/toggle }, 0) :
(
msg2 == 0x5e ? oscsend(destdevice, { b/play }, 1);
msg2 == 0x5d ? oscsend(destdevice, { b/stop }, 1);
msg2 == 0x5f ? oscsend(destdevice, { b/record }, 1);
)
);
);
msg1 == 0xb0 ? (
msg2 == 0x3c ? (
oscsend(destdevice, { f/action/992/cc/relative }, ((msg3&0x40) ? -1 : 1));
);
);
The 9th fader sends "/r24/rawfader09" because I have that OSC string mapped (with soft-takeover) to a volume plug-in in my monitoring FX chain.




{kind=link}
{kind=link}